Well… What did people think would happen after the first Trump-Ukraine scandal? That he wouldn’t hold a grudge?
Trump was sorta known for this way before he got into politics.
Well… What did people think would happen after the first Trump-Ukraine scandal? That he wouldn’t hold a grudge?
Trump was sorta known for this way before he got into politics.

I guarantee you that once they are personally affected, and I’m pretty sure they will be affected at some point, they’ll turn on this administration.
Will they?
What are their news habits? Facebook? Cable TV? Are they politically active?
A root cause of all this is that scamming/influencing is extremely effective with modern tech, especially on vulnerable people. If something bad happens, they will just get pushed down the rabbit hole waiting to suck them in.
Nothing will change until that’s regulated away, which is not going to happen now that The owners of Twitter and Truth Social are president, and Meta has their ear.

Thanks! I’m happy to answer questions too!
I feel like one of the worst things OpenAI has encouraged is “LLM ignorance.” They want people to use their APIs without knowing how they work internally, and keep the user/dev as dumb as possible.
But even just knowing the basics of what they’re doing is enlightening, and explains things like why they’re so bad at math or word counting (tokenization), why they mess up so “randomly” (sampling and their serial nature), why they repeat/loop (dumb sampling and bad training, but its complicated), or even just basic things like the format they use to search for knowledge. Among many other things. They’re better tools and less “AI bro hype tech” when they aren’t a total black box.
This is a lie.
Some background:
LLMs don’t output words, they output lists of word probabilities. Technically they output tokens, but “words” are a good enough analogy.
So for instance, if “My favorite color is” is the input to the LLM, the output could be 30% “blue.”, 20% “red.”, 10% “yellow.”, and so on, for many different possible words. The actual word thats used and shown to the user is selected through a process called sampling, but that’s not important now.
This spread can be quite diverse, something like: 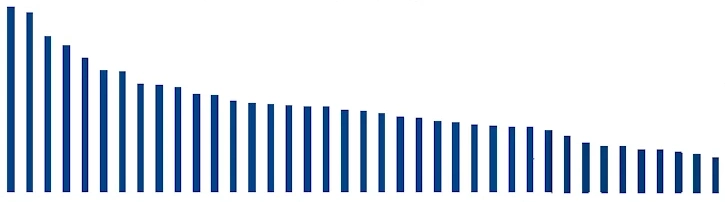
A “distillation,” as the term is used in LLM land, means running tons of input data through existing LLMs, writing the logit outputs, aka the word probabilities, to disk, and then training the target LLM on that distribution instead of single words. This is extremely efficient because running LLMs is much faster than training them, and you “capture” much more of the LLM’s “intelligence” with its logit ouput rather than single words. Just look at the above graph: in one training pass, you get dozens of mostly-valid inputs trained into the model instead of one. It also shrinks the size of the dataset you need, meaning it can be of higher quality.
Because OpenAI are jerks, they stopped offering logit outputs. Awhile ago.
EG, this is a blatant lie! OpenAI does not offer logprobs, so creating distillations from thier models is literally impossible.
OpenAI contributes basically zero research to the open LLM space, so there’s very little to copy as well. Some do train on the basic output of openai models, but this only gets you so far.
There are a lot of implications. But basically a bunch of open models from different teams are stronger than a single closed one because they can all theoretically be “distilled” into each other. Hence Deepseek actually built on top of the work of Qwen 2.5 (from Alibaba, not them) to produce the smaller Deepseek R1 models, and this is far from the first effective distillation. Arcee 14B used distilled logits from Mistral, Meta (Llama) and I think Qwen to produce a state-of-the-art 14B model very recently. It didn’t make headlines, but was almost as eyebrow raising to me.
Sad thing is that’s always been Trump’s style. His offices and buildings are all comically gaudy.